
You have probably heard of the train-test-split in the context of machine learning, which is fairly intuitive. Show some examples to your model, let it learn and then test it on other examples. But there is one more data split that is used and that is the train-validation-test split or sometimes achieved by using cross-validation. In this post I will shed light on what that is and why you would need that.
Quick definition
A validation data set is used in supervised machine learning to compare the performance of different trained models. This enables us to choose the correct model class or hyper-parameters within the model class.
Difference between train, validation and test set
The set of all available data points with labels is needed for multiple purposes:
- the models themselves need data to learn about the given task (training)
- but we ultimately want to know which model would be best “in the wild” on unseen data (validation)
- and we want to know how good the model is (testing)
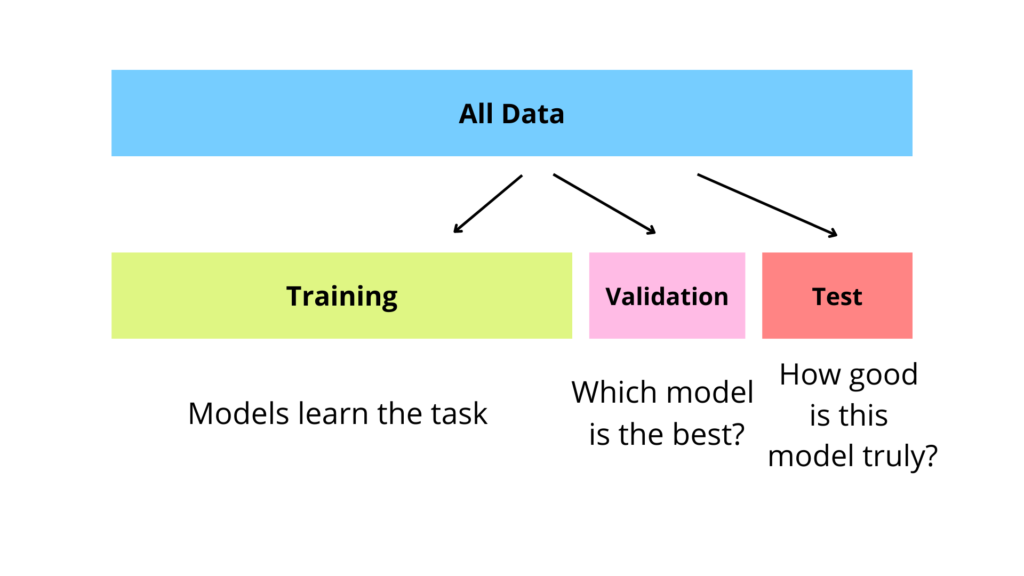
For each of these tasks we use a different subset of our total data set. But why can we not use the same data for all 3 tasks? Let’s look at that with an example:
Why can we not compare training errors instead to find the best model?
Imagine a group of students and we want to send one of them to a national competition. Ideally the best one, because we want to win.
To prepare them for the competition, you give all of them example questions to practice – possibly from the competitions of previous years. We want to be fair so of course we give each student the same practice questions.

After they practiced for a while, we still need to know who is the best. Now of course we could quiz them on these practice questions (which would be the training set), but how do we know if the student just learned all the practice answers by heart or actually understood the material and can apply it in the competition? That’s why we use a different set of questions to determine the best student: the validation data.
What more does the test data tell us?
In our student example the test data would be a last secret set of questions we could ask our chosen student to solve. Given that the questions are close to what will be asked in the final competition – which is of course always the requirement on machine learning data – the performance of the student on this data set will give us a good estimate of how the student will score in the competition.

Maybe it is very unlikely that they would win and the travel costs would be too much, so we decide we are not going to compete this year at all.
This may sound cruel in our student example, but in a machine learning setting a poor test score could mean that we need to rethink the task we want to solve and collect better suited data for training, because it would not be advisable to put a model with a ~50% test success in a position where it can make decisions for our company.
What you definitely are not allowed to do is tweak or chance the model again just because you do not like the outcome on the test. Then you would use the test set for validation and you had no way of truly testing your final model anymore. This problem is called “data leakage”, in case you want to look it up.
A good test score on the other hand can tell us that we can go ahead and use the models predictions for the intended task without too much worry.

1 comment